Archiving Online Evidence of Human Rights Violations: How OSR4Rights Tools’ Auto Archiver Saves Investigators Time and Money and Meets the Latest Guidelines on Online Investigations
Online open-source information has transformed how human rights organisations and civil society actors identify, gather, and preserve evidence of international crimes and human rights violations across the globe.
Open-source information has been praised for its ability to bypass traditional information gatekeepers to retrieve information on international crimes and human rights violations through free and publicly accessible videos, photographs and social media posts. One major challenge that investigators face is the transient nature of social media evidence, which can be removed from the internet without warning.
Recently published guidelines by the International Criminal Court’s Office of the Prosecutor, Eurojust, and the EU Genocide Network entitled, ‘Documenting International Crimes and Human Rights Violations for Accountability Purposes: Guidelines for Civil Society Organisations’ provides useful tips on ways that civil society actors can collect, document and preserve information that can be used as evidence in future national and international prosecutions. On online investigations, the Guidelines recommend ‘the use of tools specifically developed to collect and preserve online content for accountability purposes.’ According to the Guidelines:
Online information is highly volatile – it can disappear from the internet or be easily modified. Therefore, capture online information in such a way that enables the authenticity and the integrity of the digital item to be established as collected at a certain time from a certain web location.
To this end, the Guidelines recommend using digital tools that allows human rights investigators to “download the online content, collect the relevant metadata, hashtag the information and create a digital package.”
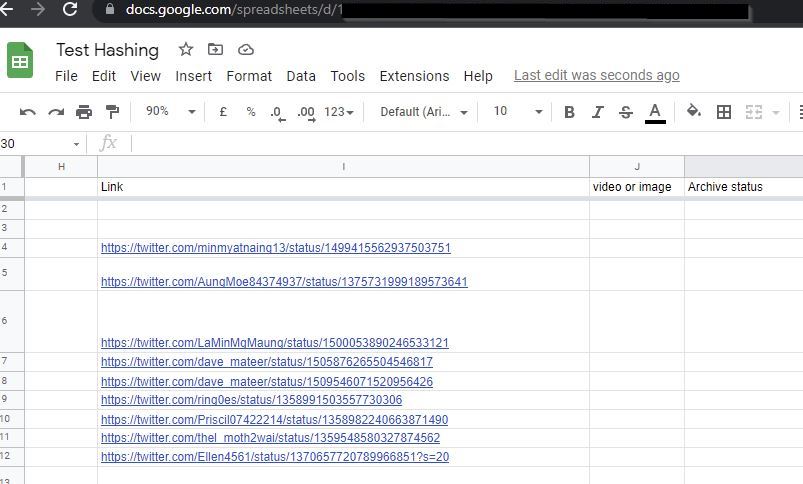
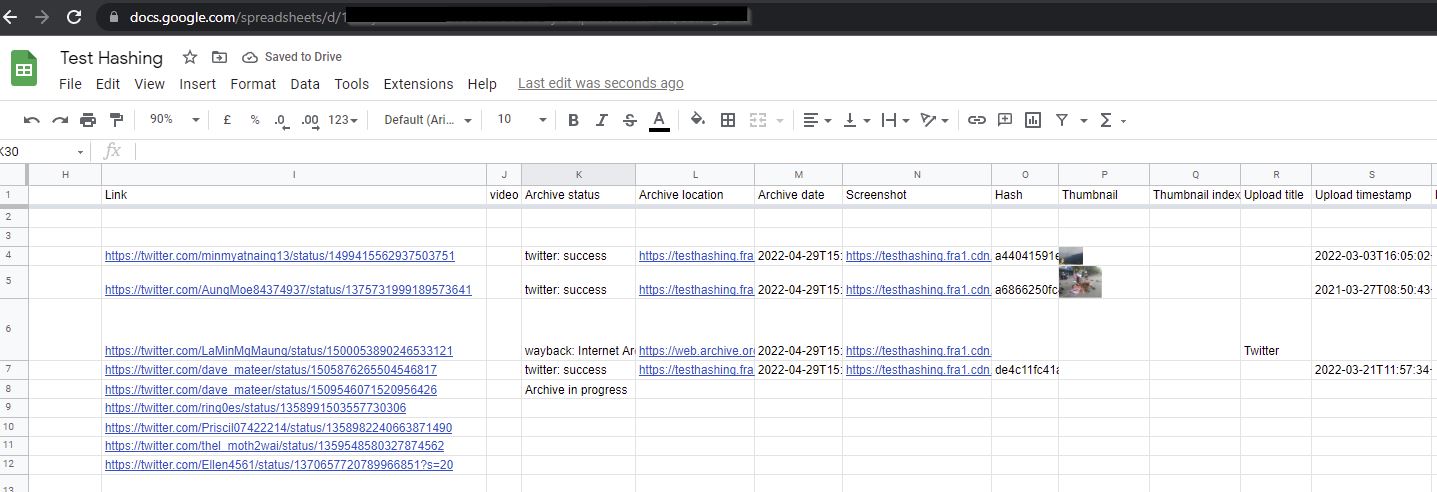
If you are wondering whether such specialised tools exist, then look no further because with our version of Bellingcat's Auto Archiver, which we contribute to. Human rights investigators can automatically save web page links by entering the Web URL links of the online information into a simple Google Spreadsheet. More advanced archiving services are provided by groups like Mnemonic, but this is a good web-based ‘quick stop’ solution that will be helpful for many human rights investigators.
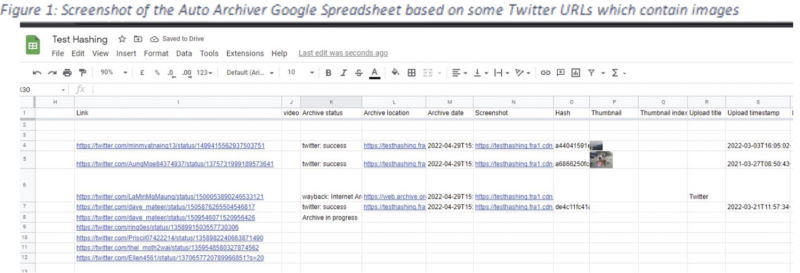
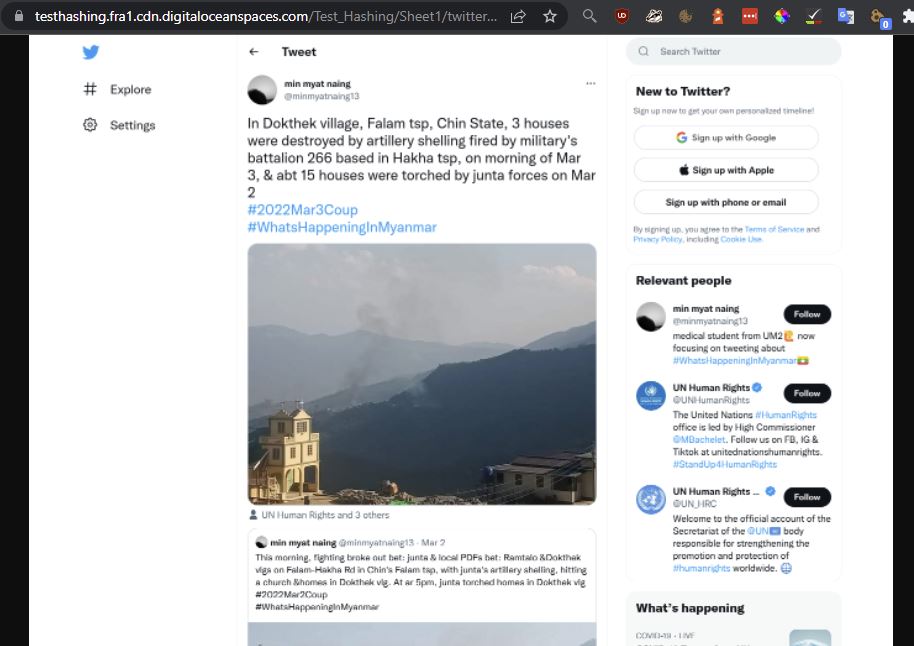
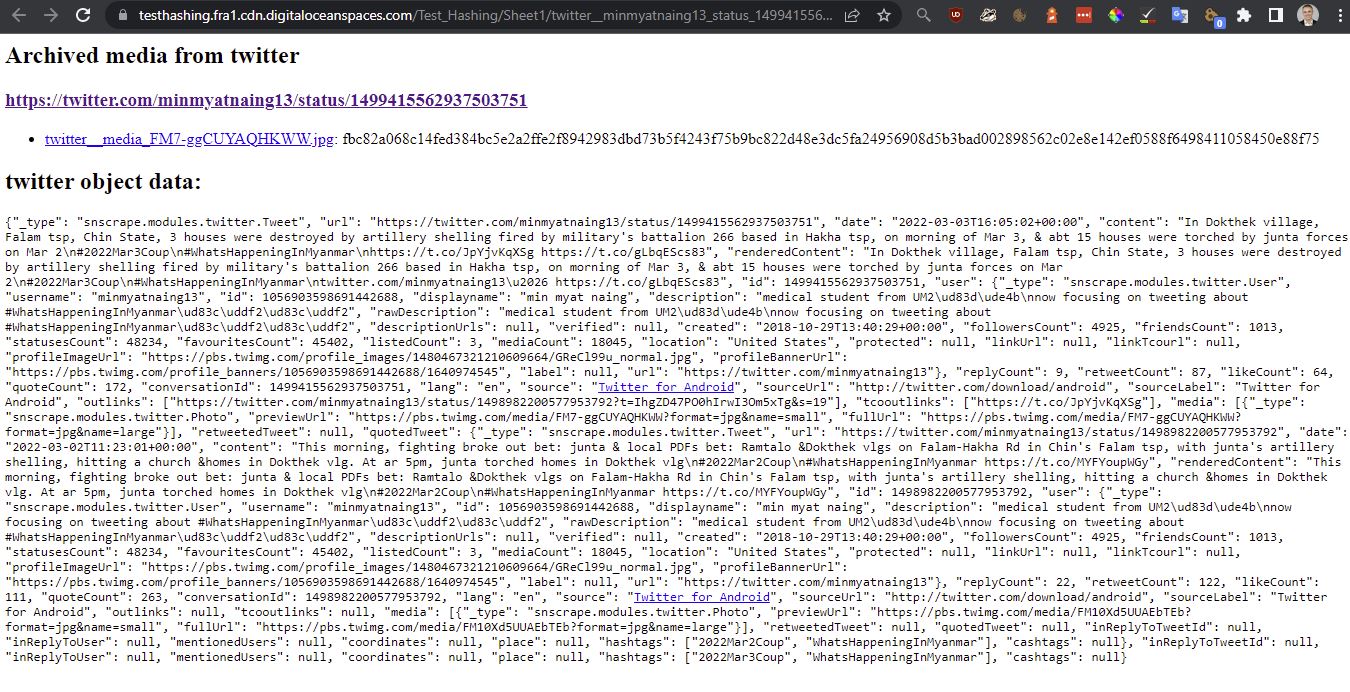
The best feature of Auto Archiver tool is that it is automatic and it is on the lookout for links that requires processing every 60 seconds. Having identified a new link in the spreadsheet, Auto Archiver automatically saves a screen shot of the link, downloads and saves a copy of the relevant media (e.g. a video or photograph uploaded with a Tweet), saves information about the metadata of the post, and creates a cryptographic hash of the content.
As a result of these steps, Auto Archiver can save human rights investigators huge amounts of time that was previously used in archiving data from sites manually.
To find out more about how the Auto Archiver tool can support your organisation’s work on human rights investigations or for a quick demonstration of the tool, please contact the team at: Yvonne.McDermottRees@swansea.ac.uk